Patrick heads the AI Division at Samsung SDSA. On the side of AI Engineering, he is responsible for Brightics AI Accelerator, a distributed AI training and automated ML product, and AutoLabel, an automatic image data annotation and modeling tool. On the side of AI Sciences, he leads the consulting group that makes AI models for our customers for many diverse use cases. Among his other responsibilities is to act as a visionary for the future of AI at Samsung. Before joining Samsung, Patrick spent 15 years as CEO at Algorithmica Technologies, a machine learning software company serving the chemicals and oil and gas industries. Prior to that, he was assistant professor of applied mathematics at Jacobs University in Germany, as well as a researcher at Los Alamos National Laboratory and NASA’s Jet Propulsion Laboratory. Patrick obtained his machine learning PhD in mathematics and his Masters in theoretical physics from University College London.
Some novelty of artificial intelligence (AI) is announced on a weekly basis. It seems that there is a race, if not an arms race, to develop ever more powerful tools and models. Some 10 years ago, anyone wanting to do AI would find themselves digging into mathematical details and writing lots of code. In practical AI, where we want to solve a problem using AI, this has changed fundamentally.
The challenge of designing and setting up the hardware systems required for the heavy computing requirements is done by the cloud providers. What used to take weeks of careful design and significant capital expense, is now a few clicks and a monthly invoice. In fact, the movement from capital to operating expenses and the ability to dynamically increase or decrease the number of servers you are using are the two primary reasons for the development of the cloud in the first place.
The third reason for having a cloud is the promise of ease-of-use as people can be anywhere in the world and still work on the same environment – the data and software do not have to move. This facilitates collaboration in dispersed teams and has been a boon during the pandemic.
Beyond making sure that the hardware is available, any cloud must provide cyber security – providing access only to authorized users and only to the resources meant for them. This is a point of contention as this has always been, and will remain, an arms race between people trying to circumvent this and people trying to make systems more secure. It is safe to say that the cloud is more secure than any on-premise data center. The simple reason is that most companies try to save money on the system administration staff whereas cloud providers have security specialists.
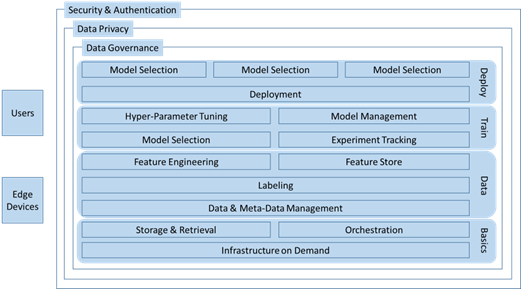
The topic of security is tightly connected with data privacy and data governance. Many data sets fall under the regulations of data privacy by which individuals have the right of control over how their data is collected and used. The precise rules differ from country to country, making this a very complex field. Whether or not certain data analysts must have access to the data, or certain parts of the data, is also covered by this aspect.
Data governance addresses the need for high quality data. Data is of high quality if it is up-to-date, correct, uniform (e.g. same format), consistent (non-contradictory), complete (all important attributes are there), and representative for the situation to be modeled using AI. Assuring these items is not easy and may require multiple processing and validation steps. To keep track of where certain data came from or how it was generated, we often collect data about the data, so called meta-data. This must be managed as well and has given rise to the cottage industry of meta-data management.
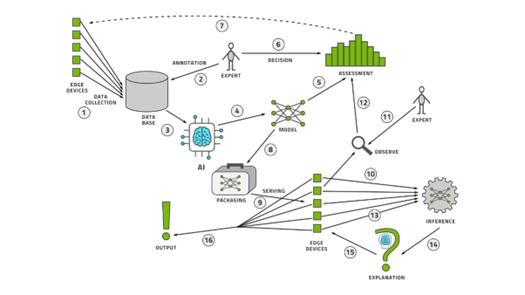
The final preparatory step before doing “real” AI is data labeling. This is where human experts in the vertical domain input some of their knowledge. Labels are a type of data that cannot be collected from a machine like a sensor or a camera but must be provided by a human. An example would be to draw an outline around a traffic sign on a street photograph and to identify it as a stop sign – many such labeled images can then be used to train AI to identify stop signs.
As many AI and data practitioners know well, once we are at this point – having a secure, private, labeled, and high-quality dataset – we have done over 80% of the human work in any AI project. This is why modern AI has recently been called data-centric AI. Traditional AI was obsessed with algorithms and mathematics and much of the literature focusses on those topics. Recently, it has become clear however that the success or failure of a real-world AI project rests squarely on the quality of the dataset. To abuse a common adage, if you have an hour to do some AI, spend 55 minutes on cleaning your data and 5 minutes running an algorithm.
Making or training an AI model involves three basic steps. First, we transform the data into the most representative form suitable for the purpose of the AI model. This may involve generating more columns by combining existing columns of data or removing columns. These methods are known as feature engineering. Second, the best type of model is chosen from the large zoo of possible models in AI, known as model selection. Third, the parameters of training method or algorithm must be tuned to the model and dataset, known as hyper-parameter tuning. The last two steps can only be done in trial-and-error fashion and account for most of the famous computational footprint of AI.
Dealing with the computational footprint can be made significantly more effective if the flow of data from the storage device to the computational device is made as smooth as possible. Several modern storage and retrieval systems have been built to accommodate this. Coordinating several computers into a cluster is helpful and so orchestration software is necessary.
To track the decisions made and lessons learned during feature engineering, we may use a feature store. To coordinate all the trials in selecting the model and tuning the parameters, we often use an experiment tracking tool. Ultimately, we select a model as the final outcome of the process. As any data set is going to grow over time, we will most likely go through this process every few weeks or months and so a sequence of models will result. A model management tool is used to track what models were made and which models are currently in use. To put models to use, we must have a model deployment mechanism depending on our application. Especially when using many models in many distributed devices, model management is crucial.
When a model is used out in the wild, as we like to say, it should be monitored. The reason is what is known as model drift. The model is, of course, a static entity but the world is not. The real-life data that the model is exposed to will be somewhat different – and may become more and more different as time goes by – than the training data. The accuracy suffers over time and the model eventually must be replaced. This is the domain of observability.
Often the users desire to know why a model gave a certain output and so AI models or outputs must be explainable. What this means depends highly on the problem that the model attempts to solve but it is often a descriptive text in human language somewhat akin to what we humans might call an explanation.
Finally, as responsible citizens, our models and applications should adhere to some ethical standards. The budding field of AI Ethics proposes many interesting ideas on how mitigate ethical risks in exposing AI models to the real world. Regulatory bodies around the world are currently legislating this and ethics is quickly becoming a requirement.
Instead of having to assemble all these 17 main topics with their dedicated tools and perhaps several more to have everything interoperate, clouds provide you with an ecosystem that already has many of these tools so that you can focus on building your model, instead of spending your time building the factory for building your model. These are the elements in the architecture of an AI Cloud.